Research projects in the lab promote three main lines of investigation:

Understanding the molecular basis of cellular identity in the normal human brain
These projects aim to define the molecular basis of cellular identity in the normal human brain. We develop and apply new computational methods to perform large-scale meta-analyses of human brain transcriptomes from bulk and single-nucleus samples. Through these analyses, we seek to identify reproducible neurobiological cell types and cellular processes, along with their optimal marker genes. We also generate large, standardized gene expression datasets from human brain samples using multiscale sampling strategies and robotic automation. The overarching goal of these efforts is to develop statistical models that can predict the cellular composition and gene activity of human brain samples. These models will provide a data-driven framework for quantifying the cellular and molecular effects of diverse neuropathologies, as well as cellular and molecular differences between stages of brain development and among brains from different species.

Developing novel treatments for brain cancers
These projects seek to identify and exploit the molecular features that most consistently distinguish malignant cells and nonmalignant cells of the glioma microenvironment from their normal counterparts. We perform large-scale meta-analyses of glioma and normal human brain transcriptomes from bulk and single-cell / single-nucleus samples to determine the affinities with which individual genes are expressed by distinct cell types. We also study intratumoral heterogeneity and clonal evolution by analyzing genetic, epigenetic, and transcriptional features in large, multiomic, and multiscale datasets produced from individual human glioma specimens with robotic automation. The goal of these efforts is to identify and validate novel therapeutic targets and reagents for treating malignant gliomas.
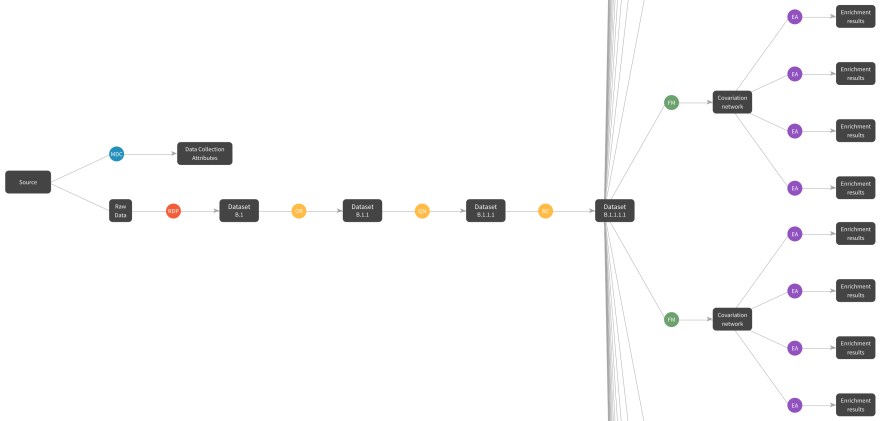
Changing the way that scientists communicate around data analysis
These projects aim to advance a cloud-based data science platform to change the way that scientists communicate around data analysis. We are motivated by the reproducibility crisis, which is driven in part by antiquated forms of scholarly communication, and the belief that computational research activities should be completely reproducible. By creating an integrated repository for structured data, standardized metadata, and curated code, we seek to enable visual, intuitive, and interactive representations of bioinformatic workflows, while simplifying data/code discovery, accelerating data analysis, building community, and guaranteeing reproducibility. We are working closely with a professional software development company and UCSF IT to develop this platform within the UCSF AWS Secure Enterprise Cloud environment.
